joinedload를 사용한 SQLAlchemy 쿼리 최적화
SQLAlchemy는 파이썬(Python)용 Object Relational Mapper다.
ORM(Object Relational Mapper)은 객체(Object)와 관계형 데이터베이스(RDB - Relational Database)의 데이터 타입을 연결해 주는데,
이게 나오기 전엔 개발을 어떻게 했었나 싶을 정도로 아주 편리하다.
사용법도 간단해서 짧은 코드로 쿼리를 날리면 모델 하나를 딱 불러온다.
Model.get(model_id)정말 좋다.
아무런 문제가 없었다.
적어도 외부 DB를 사용해 시험해 보기 전엔 그랬다.
외부 DB는 요청을 보내고 받는 시간이 길다.
헌데 SQLALCHEMY에서 자동으로 만들어 주는 쿼리를 쓰면, 너무 많은 요청을 보내게 된다.
그렇다면 성능을 향상하기 위해선?
요청 수를 줄이면 된다.
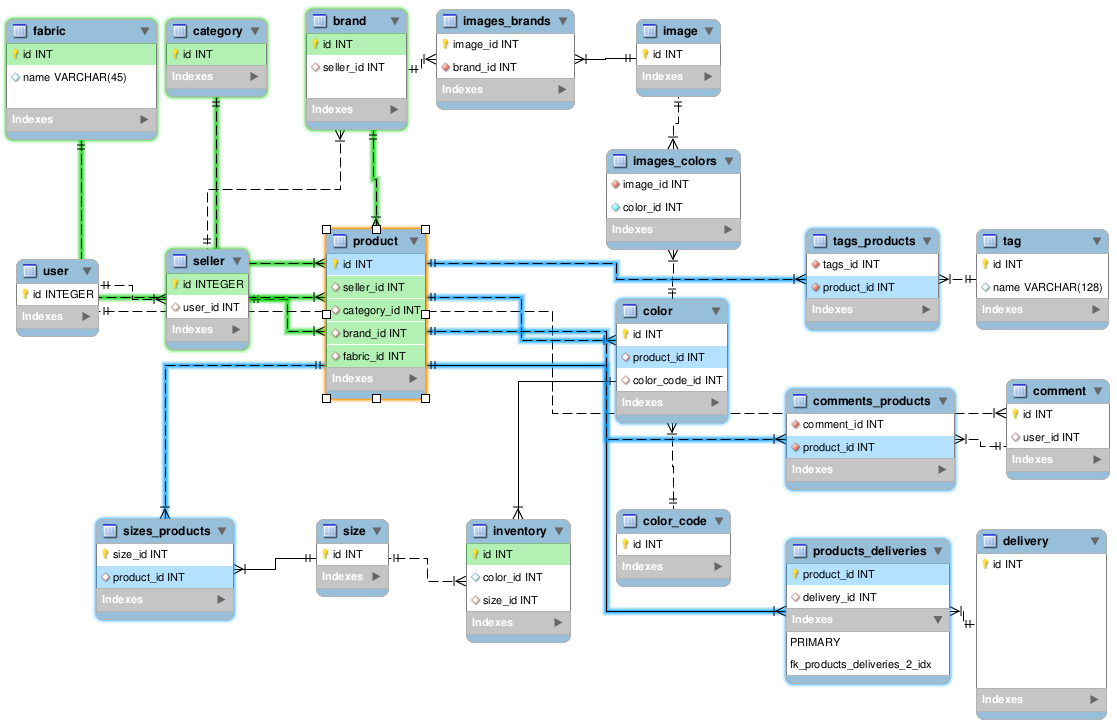
예제의 product테이블은 여러 테이블과 연결되어 있는데,
쿼리를 날려 product와 관련된 테이블의 정보를 모두 불러와야 한다.
Sqlalchemy의 기본 쿼리 설정은 select로 연관된 table을 독립된 SELECT쿼리로 호출하지만,
응답시간이 느린 외부 DB를 쓴다면, 이를 join해서 쿼리 개수를 줄이면 된다.
sqlalchemy에서 join은 어떻게 하는가?
모델을 생성할 때 lazy='joined'를 써서 관련 테이블을 부를 때 join하는 방법과,joinedload를 이용한 join 방법이 있다.
모델 생성 시 lazy를 사용해 join한 경우, 모델 호출 시마다 join이 되므로,
예제에선 필요한 상황에만 쿼리를 join하는, joinedload를 사용했다.
joinedload 간략 사용 방법
Model.query.options(db.joinedload(Model.relatedModel).all()SQLAlchemy 쿼리 최적화 방법
- 1..1 관계는 innerjoin한다.
db.joinedload(Seller, innerjoin=True) - 1..n 관계는 innerjoin하지 않는다.
db.joinedload(Tags) - 1..n 관계에서 관계가 깊다면, subqueryload를 써서 관련 테이블을 불러오고,
그에 대해 joinedload를 해준다.
db.subqueryload(Colors),
db.joinedload(Colors, Inventory)

위 방법을 써서 Call 개수를 25% 줄였다.
보통 Call이 29~30개가 나오다가, 22로 줄었으니, 약 7.5개 준 것이다.
Call당 시간이 얼마나 걸리냐에 따라 시간 단축이 가능한데,
테스트 환경에서 0.08초 정도 걸렸으므로 약 0.6초(0.08 * 7.5) 의 시간을 단축했다.
이건 데이터베이스의 응답 지연이 얼마나 되느냐에 따라 더 큰 차이를 보인다.
물론 로컬 db에서는 percall시간이 아주 짧으므로(테스트 환경에선 0.001초) 이런 최적화 차이를 체감하지 못한다.
참조
http://docs.sqlalchemy.org/en/rel09/orm/relationships.htmlhttp://docs.sqlalchemy.org/en/rel09/orm/loading.html
http://stackoverflow.com/questions/6935809/how-to-use-joinedload-contains-eager-for-query-enabled-relationships-lazy-dyna
http://invenio-software.org/wiki/Tools/SQLAlchemy/Performance
by 月風